Prologue
SQL 코드카타 문제를 풀고, 만든 대시보드를 튜터님의 설명을 들으며 수정했다. 필터를 워크시트 전체에 적용할 수 있는 점이 놀라웠다. 이래서 태블로를 쓰는구나 싶었다. 또한 대시보드의 인사이트를 도출해보았다. 그 과정을 적어보려 한다.
SQL 코드카타
91번 홀수인 id, 아닌 조건 설정하기
출처: not boring movies
영화 정보를 담고 있는 테이블에서 id가 홀수이면서 description이 'boring'이 아닌 영화를 조회해야 했다.
- MOD(나눌 값, 나누는 수) -> 나머지 출력
- NOT(조건) -> 조건이 아님
두 개를 활용하여 코드를 작성했다.select * from Cinema where (MOD(id, 2) = 1) and not(description = 'boring') #odd number and not boring order by rating desc
92번 가격 정보, 판매 정보가 있을 때 평균가 구하기
- 가격 정보가 시간대 마다 달라서 join할 때 product_id가 같다는 조건에
구매 날짜가 가격표 날짜의 조건에 있다는 추가했다. - product_id 별로 그룹을 묶어서 unit과 price를 곱하여 총매출을 계산했고,
총 수량을 나눠서 평균 가격으로 만들었다. - null값이 나오면 0으로 처리하기 위해
ifnull을 사용했다.SELECT p.product_id ,IFNULL(ROUND(SUM(price * units) / SUM(units), 2), 0) average_price FROM Prices p LEFT JOIN UnitsSold u ON p.product_id = u.product_id AND (u.purchase_date BETWEEN p.start_date AND p.end_date) GROUP BY p.product_id;
태블로 특강 대시보드 다시 만들기
태블로 데스크탑에 CSV 파일 업로드
파일 - 새로 만들기 - 데이터 연결 - 파일에 연결 - 자세히
순서대로 클릭한다. 파일을 클릭한다.

한 번 통합 문서 파일을 만들어두면 데스크톱 첫 화면에 해당 파일이 나타난다.
그때부터는 한 번 클릭으로 해당 파일 편집화면으로 들어올 수 있다.
사용하지 않을 필드 숨기기
클릭 후, Shift를 누르며 클릭을 하여 필드를 범위로 선택한다.(윈도우 파일탐색기와 같이 작동함)
우클릭 후 숨기기로 필드를 숨김 처리한다. 언제든지 취소할 수 있으니 쫄지말자.
숨김으로 테이블을 12개 필드로 줄였다.

워크시트1. 유입 채널별 트래픽
도넛 차트로 채널별 방문자 수 파악하기.
방문자를 식별하는 PK인 Full Visitor ID를 차원 -> 측정값으로 변환 후
집계 속성을 카운트(고유)로 설정한다.
상수 1로 축을 만든 후, 파이차트로 설정하고 색상과 각도에 채널 그룹, 카운트 PK 필드를 둔다.
레이블도 같은 필드를 끌어 놓아 수치를 표시한다. 최대한 많이 대비되지 않는 색상들로 할당한다.
상수 2로 2번째 축을 만든 후, 작은 하얀 원을 만든다. 그리고 전체 고유 수를 레이블로 두어 표시한다.

워크시트2. 시간대별 트래픽
히트맵으로 시간대별 방문자 수 파악하기.
시간대 정보를 포함하고 있는 필드 Visit Start Time 활용.
Unix 형식(1970년 1월 1일 기준으로 지난 초를 정수 형식으로 표현) -> UTC형식(2025-02-13 00:00:00)
으로 변환하기.
DATEADD('second', [Visit Start Time], #1970-01-01#)열에 요일, 행에 시간 단위로 UTC 형식으로 변환한 필드를 끌어놓는다.
색상에 고유 카운트한 Visitor PK 필드를 끌어놓으면 히트맵이 완성된다.

워크시트3. 채널과 디바이스별 트래픽
채널, 디바이스 2개의 수준에서 사용자의 방문 수를 집계한다.
LOD식을 활용한 필드를 만들어서 어떻게 LOD가 적용되는지 파악한다.
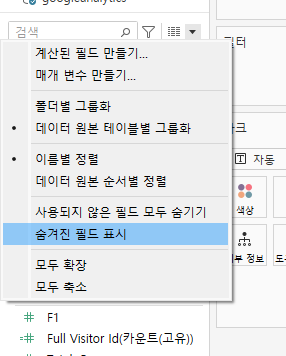
숨김 처리된 device.deviceCategory를 숨김 해제해준다.
데이터 탭 상단의 드롭다운(아래 화살표) 단추를 눌러 숨겨진 필드 표시를 통해 원래의 열을 확인한다.
필드 옆의 눈 아이콘을 클릭해 숨김을 해제한다.
태블로 과제 해설 강의
데이터 연결
데스크톱에서 - 새 파일 생성 - 데이터 연결 - 파일(국가 주요 지표) 선택하기.
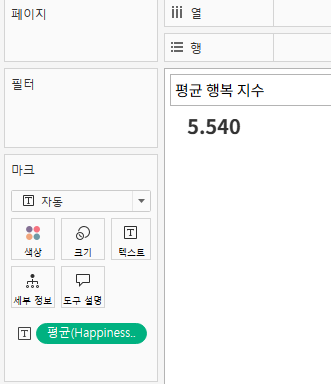
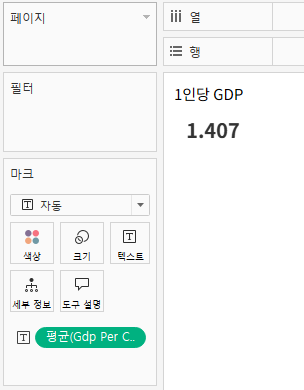
워크시트1~3. 주요 평균 지표
- 평균 행복점수
- 평균 GDP
- 평균 건강한 삶 기대 수명

워크시트4. 지역별 평균 행복점수
지역을 차원으로, 막대 그래프는 0부터 거리를 표현하기 때문에 평균 행복점수 측정값으로 넣는다.
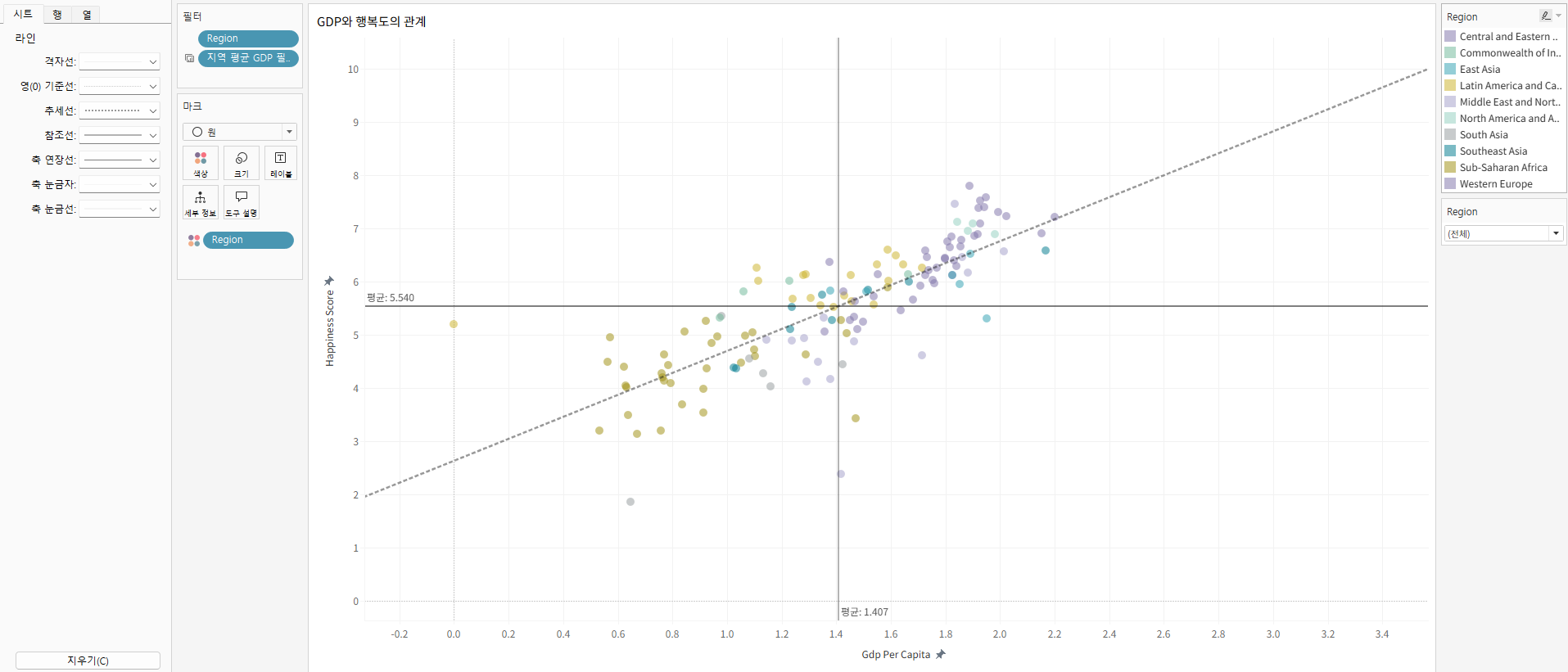
워크시트5. GDP와 행복점수
산점도로 GDP, 행복점수를 표현하여 관계를 확인한다.
차원은 명목형 변수, 측정값은 데이터의 값(연속형 변수)라고 생각하면 쉽다.
색상의 불투명도를 조정하면 연함과 진함의 대비를 통해 밀도를 확인할 수 있다.
만든 워크시트를 대시보드로 제작
지표를 넣을 때, 컨테이너로 넣어야 한다. 컨테이너 밖인지 안인지 확인?
필터 만들기: 워크시트에서 필터 생성, 대시보드로 이동해서 해당 워크시트의 드롭단추-필터 클릭
워크시트 필터를 전체 필터로: 필터 드롭단추 - 이 데이터 원본을 사용하는 모든 항목
원하는 워크시트만 선택해서 필터를 적용할 수도 있다.
관련 데이터 원본을 사용하는 모든 항목을 적용하면 Join, 연결된 다른 데이터를 사용하는 워크시트도
필터가 적용된다.
국가 GDP가 대륙별 평균 GDP보다 높은지
지역별 평균 GDP를 기준으로 평균 초과, 평균 이하로 구분하는 계산된 필드를 만든다.
틈새 데이터 설명
대륙이 western europe이라고 하면 그 대륙에 해당하는 국가는 여러 개가 있다.
핀란드, 덴마크, 스웨덴 등...
사용하는 데이터의 각 행은 전 세계 국가의 GDP, 평균지수, 건강 기대 수명을 포함하고 있다.
이름은 지역별 평균 GDP 필터라고 설정한 후 계산식을 아래와 같이 넣는다.
IF [Gdp Per Capita] > {FIXED [Region] : AVG([Gdp Per Capita])}
THEN '평균 초과'
ELSE '평균 이하' END지역 평균 GDP 필터를 대시보드에 표시
: 하나의 워크시트에 계산된 필드를 필터로 추가하고, 대시보드의 드롭단추를 눌러 대시보드에 표시한다.
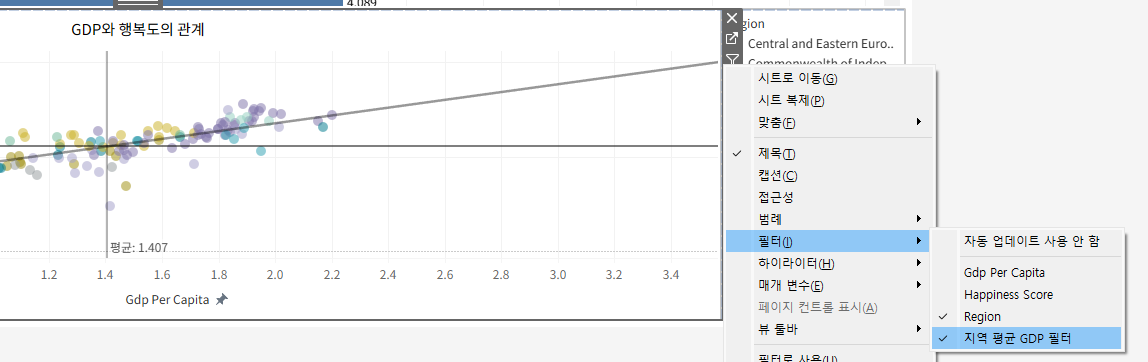
워크시트 전체에 적용
: 필터 드롭단추 - 워크시트에 적용 - 선택한 워크시트 - 대시보드의 워크시트 전체를 선택한다.
산점도의 참조선과 추세선 긋기
산점도에서 평균과 추세를 확인하기 위해 각각의 선을 그어준다.
평균 참조선
: 분석 - 참조선을 통해 행과 열의 평균을 나타내는 참조선을 그을 수 있다.
필드 간의 관계를 나타내는 추세선
: 분석 - 추세선을 통해 각 지역별 모든 선을 그린다.
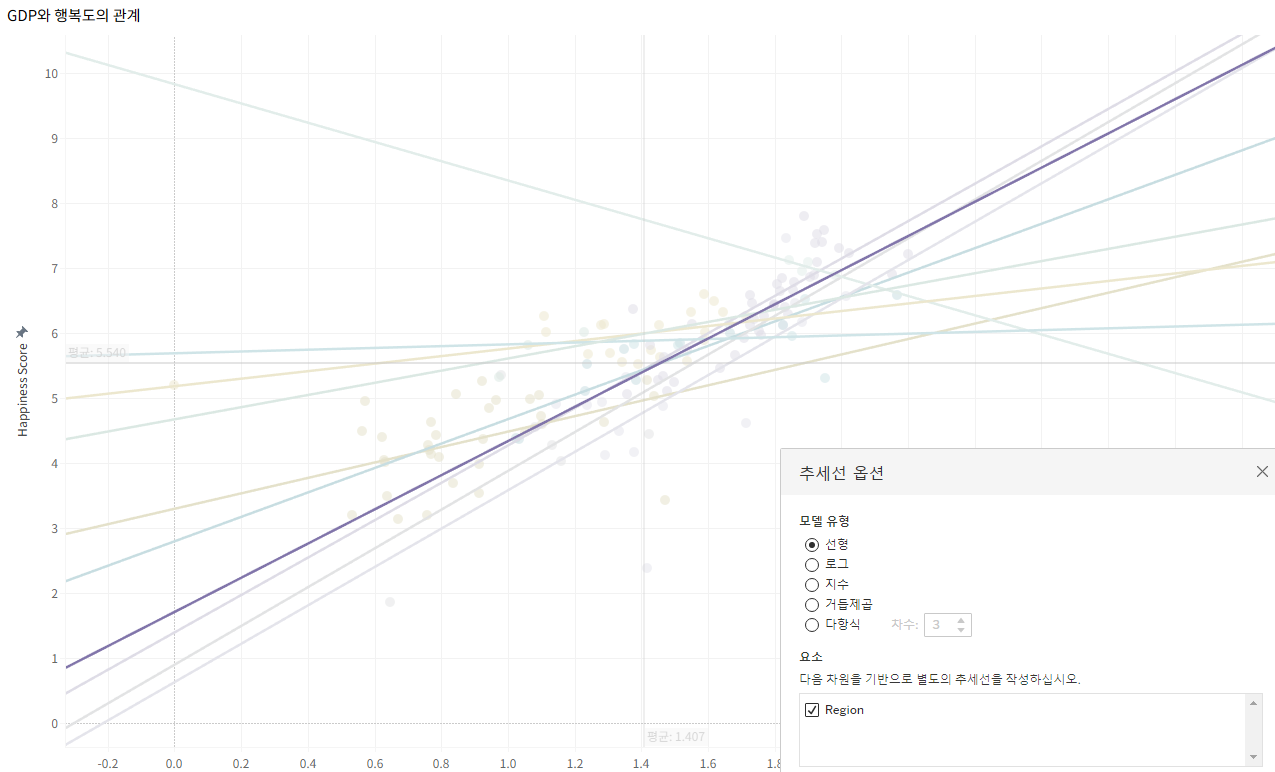
하나의 선을 우클릭 - 모든 추세선 편집 - 요소 - 구분하고 있는 차원을 선택 해제하여
모든 데이터의 추세를 나타내는 선 1개로 만든다.
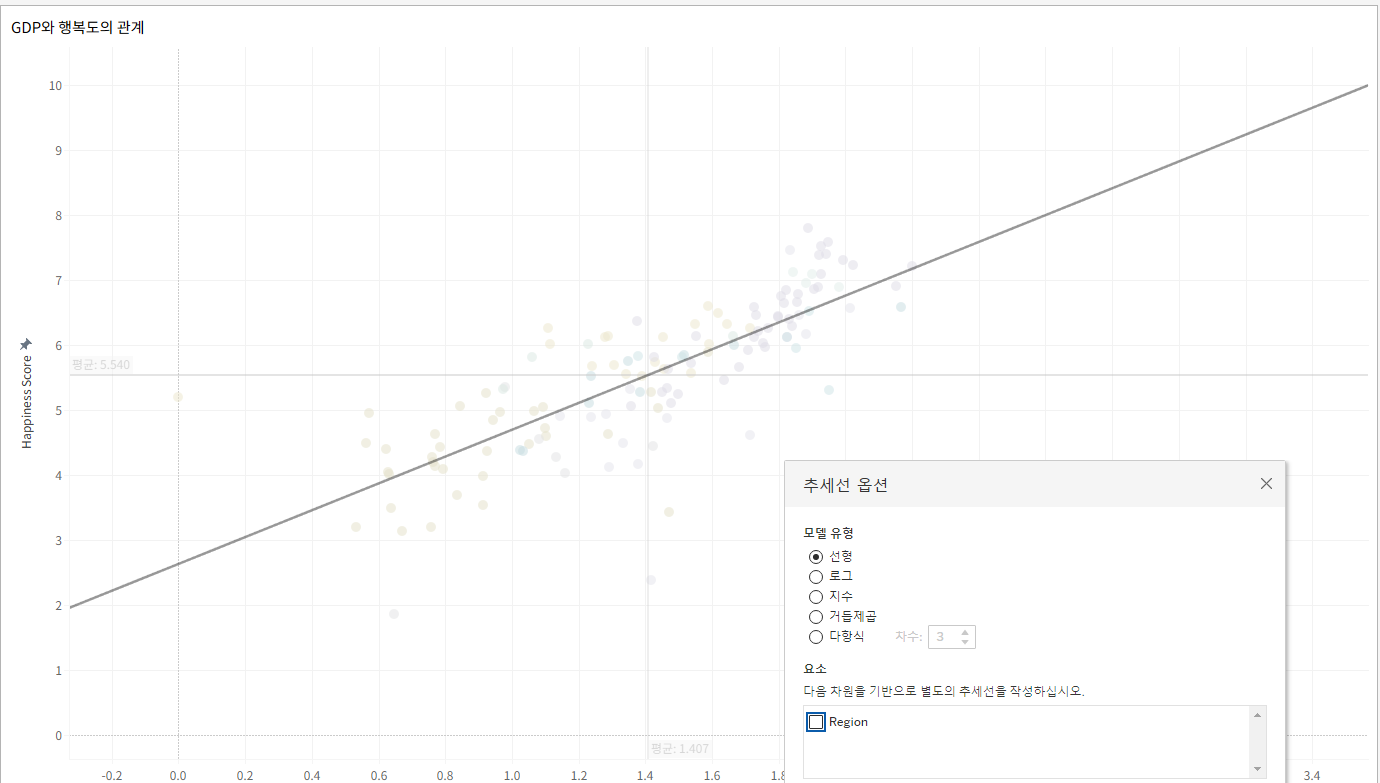
추세선을 점선으로 표시해서 평균선과 구분하고 예상의 의미를 전달한다.
: 서식 - 라인 서식 - 추세선 - 점선 선택
막대 차트 색상 편집
지역을 색깔로 구분하자.
대비가 크지 않은 색끼리 크기별로 구분한다.
지역에 따른 색 구분
: 색상에 지역 필드를 끌어놓기
지역마다 색깔 부여
: 지역을 두번 더블 클릭, 색상을 RGB 값으로 할당할 수 있다.
다만 일일이 색상을 편집하는 것은 수작업이다.
우선은 태블로 20처럼 기본 색상표를 할당 후, 불투명도를 50%로 낮춰서 파스텔 톤으로 바꾼다.
색이 너무 강조가 되지 않으면서도 지역별로 구분이 된다.
마지막으로 워크시트 글꼴 편집
통합 문서 전체 글꼴 변경
: 서식 - 통합 문서 - Notosans KR
최종 완성한 대시보드 및 인사이트
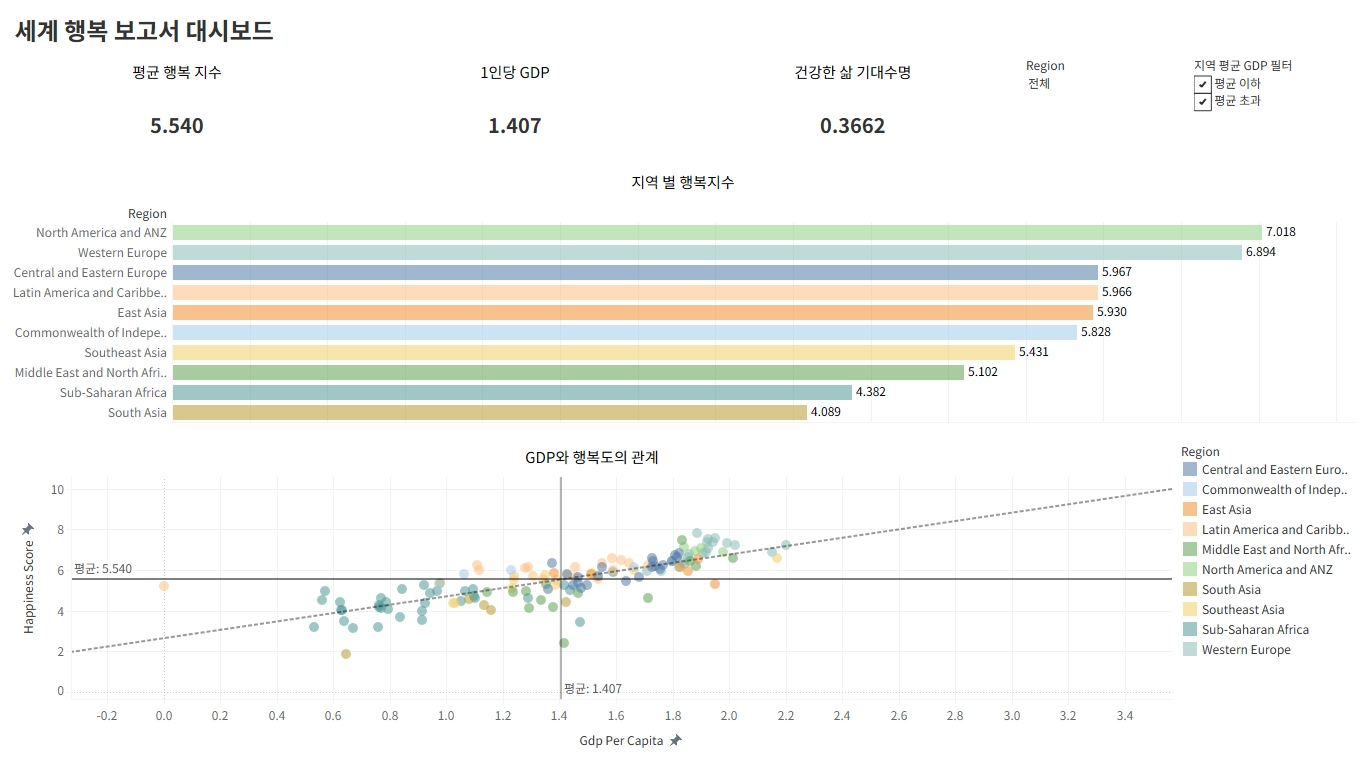
지역별 행복지수 막대그래프
: 1. 동아시아, 아메리카, 유럽 국가는 평균 행복지수보다 높다.
반면 남아시아, 동남아시아, 아프리카 국가는 평균 행복지수보다 낮다.
2. 그 이유는 아래의 GDP와 행복도의 관계 산점도를 보면 유추할 수 있다.
GDP가 높을수록 행복지수가 높다. 평균 행복지수보다 높은 국가는 모두 GDP가 높은 국가이다.
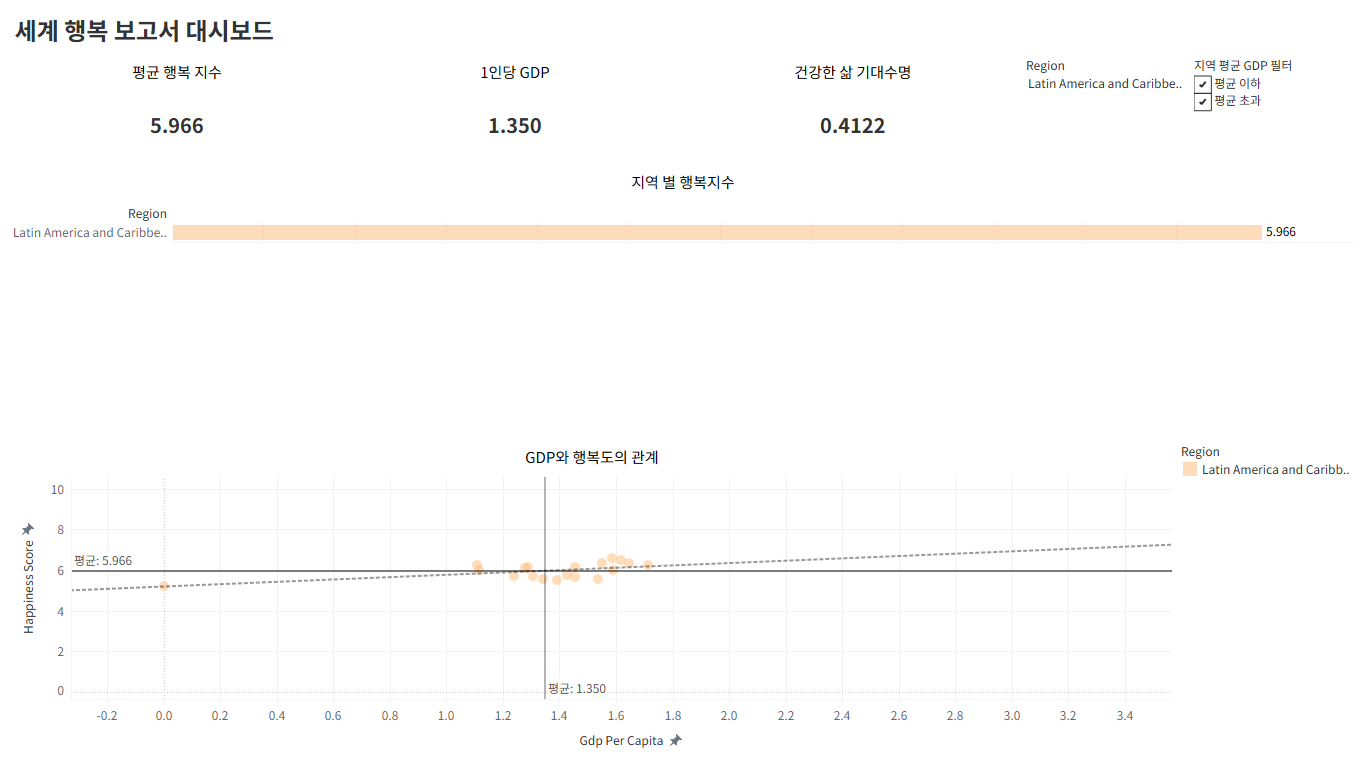
다만 예외적으로 라틴 아메리카와 캐리비안 지역의 국가는
GDP가 평균보다 낮았음에도 행복지수가 평균보다 조금 작거나 높았다.
이 국가들의 평균 행복지수(5.96)가 모든 국가의 평균 행복 지수(5.54)보다 높았다.
이 국가들의 1인당 GDP(1.35)는 모든 국가의 1인당 GDP(1.40)보다 낮았다.
추세선을 보면 GDP가 높아짐에 따라 행복지수가 높아지고는 있으나 영향이 미미한 것을 알 수 있다.
이들의 행복도가 높은 것은 GDP로 설명할 수는 없다.
- 행복지수와 GDP의 관계
GDP가 높을수록 행복지수가 높은 경향이 있으나
GDP로 설명할 수 없는 라틴 아메리카와 같은 지역도 있다. 이들의 행복지수는 경제가 아닌 문화와 같은 또 다른 요인으로 결정되고 있는 것으로 예상한다.
경제 말고도 자신을 행복하게 할 수 있는 것을 찾으면 좋을 것 같다.
'Today I Learned' 카테고리의 다른 글
| [TIL] 25.02.18 태블로로 게임 매출 대시보드 만들기 (1) | 2025.02.20 |
|---|---|
| [TIL] 25.02.17 태블로 프로젝트 2일차 (0) | 2025.02.18 |
| 25.02.16 Olist데이터 SQL 쿼리 (0) | 2025.02.18 |
| [TIL] 25.02.14 태블로 프로젝트 1일차 (0) | 2025.02.14 |
| [TIL] 25.02.12 A/B 테스트 결과 태블로로 시각화 (0) | 2025.02.13 |